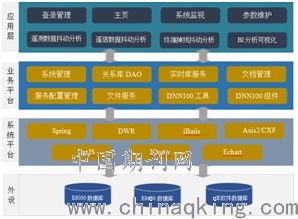

数据挖掘是一种从大量数据中提取有价值信息和知识的技术。它综合运用统计学、机器学习、数据库技术和其他领域的知识,对数据进行深入分析和挖掘。本文将介绍数据挖掘的五种主要方法,包括数据预处理、聚类分析、关联规则挖掘、分类与预测以及回归分析。

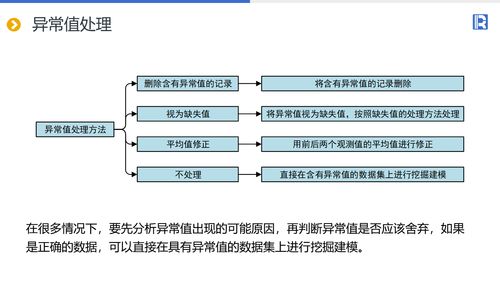
数据预处理是数据挖掘的重要步骤之一,它通过对数据进行清洗、集成、变换等操作,将原始数据转换为适合进行数据挖掘和分析的形式。数据预处理可以解决诸如数据缺失、异常值、不一致等问题,提高数据的质量和可信度。
在数据预处理阶段,我们需要根据实际情况选择合适的方法,如填充缺失值、删除冗余数据、规范化数据等。还需要对数据进行必要的转换和缩放,以便更好地进行后续的数据挖掘和分析。

聚类分析是一种将数据按照某种特征或相似性进行分组的技术。它将数据集划分为若干个簇,使得同一簇内的数据相似度高,而不同簇之间的数据相似度低。聚类分析广泛应用于客户细分、市场分析、图像识别等领域。
常见的聚类算法包括K-均值聚类、层次聚类、DBSCA等。在选择合适的聚类算法时,我们需要考虑数据的特征和数据的分布情况。同时,我们还需要对聚类结果进行评估和调整,以确保聚类的效果和质量。

关联规则挖掘是一种发现数据集中变量之间的有趣关系的技术。它可以帮助我们发现数据之间的隐藏联系和规律,为决策提供有力的支持。关联规则挖掘广泛应用于市场篮子分析、疾病诊断等领域。
常见的关联规则挖掘算法包括Apriori算法、FP-Growh算法等。这些算法通过搜索频繁项集和生成关联规则来发现数据之间的关联性。在实际应用中,我们需要根据问题的特点和数据的分布情况选择合适的算法和参数设置,以达到最佳的关联规则挖掘效果。

分类与预测是数据挖掘的重要应用之一,它通过对已知数据进行学习和建模,实现对未知数据的分类或预测。分类与预测广泛应用于欺诈检测、信用评估、疾病预测等领域。
常见的分类与预测算法包括决策树、朴素贝叶斯、支持向量机等。这些算法通过构建分类模型或回归模型,对未知数据进行分类或预测。在实际应用中,我们需要根据问题的特点和数据的分布情况选择合适的算法和参数设置,以达到最佳的分类与预测效果。

回归分析是一种研究变量之间依赖关系的技术。它通过对已知数据进行学习和建模,实现对未知变量的预测或解释。回归分析广泛应用于因果关系研究、预测模型构建等领域。
常见的回归分析算法包括线性回归、逻辑回归、多项式回归等。这些算法通过拟合回归模型来预测或解释变量的变化规律。在实际应用中,我们需要根据问题的特点和数据的分布情况选择合适的算法和参数设置,以达到最佳的回归分析效果。
 头条
头条 头条
头条 头条
头条 头条
头条 头条
头条 头条
头条 头条
头条 头条
头条 头条
头条 头条
头条