数据挖掘的具体步骤一般包括以下几个环节:
1. 数据清洗:清除掉数据中的噪音、缺失值、异常值等,以保证数据的质量和可用性。
2. 数据预处理:将数据转换为一个易于分析和可视化的格式,例如将数据归一化、标准化等。
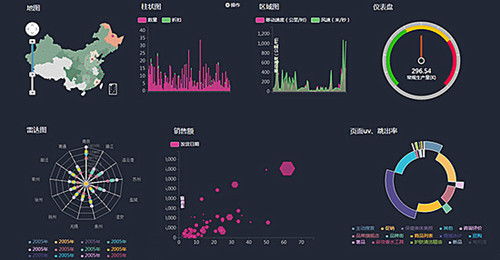
3. 数据探索:通过可视化、统计等方法,探索数据的分布和特征,以了解数据的结构和规律。
4. 特征提取:从数据中提取出与挖掘目标相关的特征,例如文本的关键词、图像的特征等。
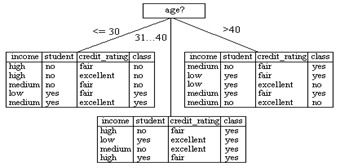
5. 模型构建:根据挖掘目标选择合适的算法,并构建模型,例如决策树、神经网络、聚类等。
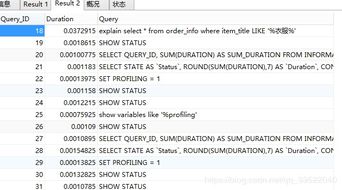
6. 模型评估:通过交叉验证、ROC曲线等方法,评估模型的性能和准确度,并根据评估结果调整模型。
7. 模型应用:将模型应用于实际数据中,并生成预测结果或分类结果等。
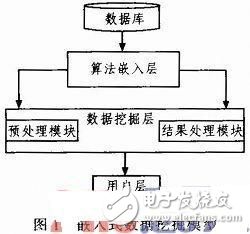
数据挖掘是一种利用统计学、机器学习等技术,从海量数据中提取有价值信息的过程。本文将详细介绍数据挖掘的具体步骤,帮助您更好地了解这一领域。

在进行数据挖掘之前,首先要明确挖掘的目标。这可能涉及到业务需求、问题定义等方面。例如,企业希望通过数据挖掘了解客户的行为偏好,以便更好地制定营销策略。在这个过程中,我们需要明确目标,并围绕这个目标收集和处理数据。

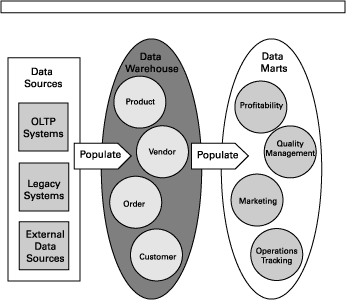
数据挖掘需要处理海量的数据,因此数据收集是一个非常重要的环节。在收集数据时,我们需要关注数据的来源、质量和完整性。同时,还需要对数据进行预处理,包括清洗、转换、归一化等操作,以保证数据的准确性和一致性。

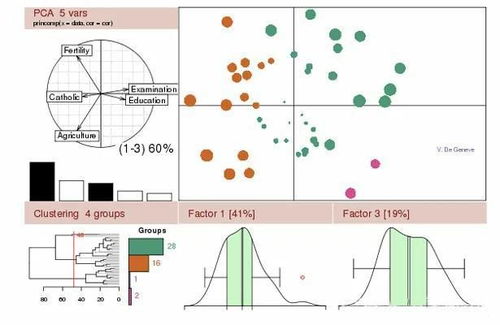
从预处理后的数据中提取特征是数据挖掘的关键步骤之一。特征是能够反映数据规律性的指标,通过对特征的提取,我们可以更好地理解数据的分布和关系。常用的特征提取方法包括统计分析、聚类分析、关联规则等。

在提取特征之后,我们需要选择适合的模型来进行数据挖掘。不同的模型适用于不同的场景和问题,需要根据实际情况进行选择。例如,决策树模型适用于分类问题,神经网络模型适用于回归问题。选好模型后,我们需要利用已知的数据对模型进行训练,以调整模型的参数和结构。

模型训练完成后,我们需要对模型进行评估和优化。评估的目的是了解模型的准确性和可靠性,常用的评估指标包括准确率、召回率、F1值等。如果模型的性能不理想,我们需要对模型进行调整和优化,以提高其性能。常用的优化方法包括交叉验证、网格搜索等。
最后一步是结果解释与应用。我们通过数据挖掘得到了很多有价值的信息和知识,但这些信息和知识可能比较抽象和复杂。因此,我们需要对其进行解释和应用,将其转化为具体的业务策略或行动计划。例如,通过数据挖掘了解了客户的行为偏好后,我们可以制定相应的营销策略,提高客户满意度和忠诚度。
数据挖掘是一个复杂而有趣的过程,它可以帮助我们从海量数据中提取有价值的信息和知识,为业务决策提供支持和参考。通过明确目标、收集和处理数据、提取特征、选择模型、评估和优化模型以及解释和应用结果等步骤,我们可以更好地应用数据挖掘技术,推动业务的发展和创新。





 头条
头条 头条
头条 头条
头条 头条
头条 头条
头条 头条
头条 头条
头条 头条
头条 头条
头条 头条
头条





![[系统教程]适合新手的Win10系统一键自动重装方法分享](/upload/images/124282120)


![[系统教程]Win11色温怎么调 Win11色温调整](/upload/images/124300053)








