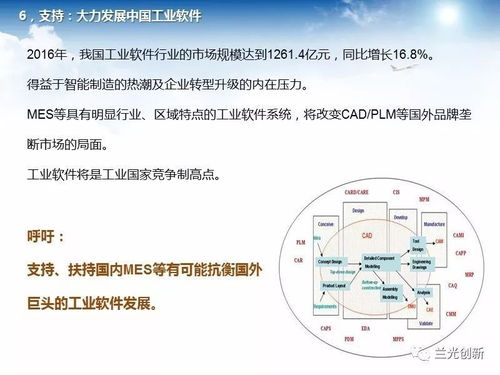
1. 案例背景介绍
随着科技的不断发展,机器学习已经成为了许多领域的重要工具。本文将以一个实际的机器学习案例为例,介绍从数据集选择、预处理到模型训练、评估和应用的全过程,以及效果评估和展望。
2. 数据集选择与预处理
在本案例中,我们选择了经典的鸢尾花数据集。该数据集包含了鸢尾花的四个特征:萼片长度、萼片宽度、花瓣长度和花瓣宽度,以及对应的鸢尾花的种类。在进行模型训练之前,我们需要对数据进行预处理,包括去除缺失值、异常值和重复值,对数据进行归一化处理,以及将分类变量转换为数值型变量。
3. 模型选择与参数优化
在机器学习中,不同的模型适用于不同的任务。对于分类问题,我们选择了逻辑回归、支持向量机和决策树三种模型进行训练。在训练过程中,我们使用了网格搜索和交叉验证等方法对模型参数进行了优化。通过调整模型参数,我们得到了最优的模型参数组合。
4. 模型训练与评估
在得到最优的模型参数组合后,我们对模型进行了训练。在训练过程中,我们使用了Sciki-lear库提供的函数对模型进行了训练,并使用交叉验证对模型进行了评估。评估指标包括准确率、精确率、召回率和F1得分等。通过评估,我们发现支持向量机在鸢尾花分类问题上表现最好。
5. 模型应用与效果评估
在得到最优的模型后,我们将模型应用于实际数据的分类中。为了评估模型的预测效果,我们使用留出法将数据分为训练集和测试集,并使用测试集对模型进行了评估。评估指标包括准确率、精确率、召回率和F1得分等。通过评估,我们发现支持向量机在鸢尾花分类问题上的预测效果最好。
6. 总结与展望
通过本次实践案例,我们展示了如何使用机器学习对数据进行分类。在数据集选择和预处理方面,我们需要注意数据的完整性和准确性;在模型选择和参数优化方面,我们需要根据任务的特点选择合适的模型和参数;在模型训练和评估方面,我们需要使用合适的评估指标对模型进行评估;在模型应用方面,我们需要根据实际需求选择合适的模型进行预测。
展望未来,机器学习将会在更多的领域得到应用。我们可以进一步探索新的算法和模型,提高模型的预测效果和泛化能力;我们也可以将机器学习与其他技术相结合,如深度学习、自然语言处理等,以实现更加复杂和精细的任务;我们还可以进一步研究和优化模型的性能和效率,以适应大规模数据的处理需求。
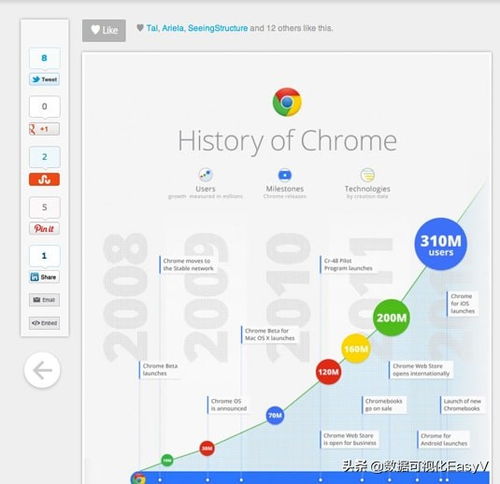 头条
头条 头条
头条 头条
头条 头条
头条 头条
头条 头条
头条 头条
头条 头条
头条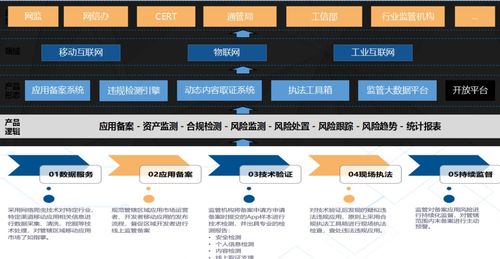 头条
头条 头条
头条