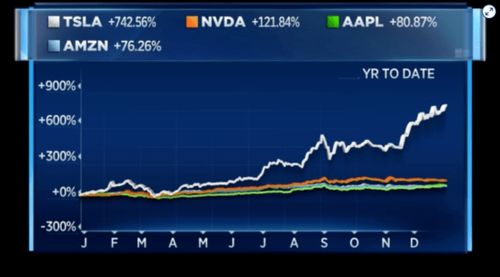
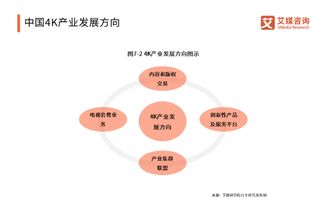
1. 案例背景介绍
本案例旨在通过机器学习技术,对一个现实世界的问题进行建模和解决。我们将介绍如何从数据集选择、预处理,到模型选择、参数优化,再到模型性能提升、部署应用,以及最后总结经验和展望未来。
2. 数据集选择与预处理
在选择数据集时,我们优先考虑具有丰富特征和标签的数据集。例如,在分类问题中,我们希望选择包含多种类别的数据集,以便模型能够学习到更复杂的模式。对于预处理,我们将包括数据清洗、特征选择、特征工程等步骤,以确保数据的质量和可用性。
3. 模型选择与参数优化
针对所面临的问题,我们将选择一个或多个适合的机器学习模型进行尝试。例如,对于分类问题,我们可能会选择决策树、逻辑回归、随机森林等模型;对于回归问题,我们可能会选择线性回归、支持向量回归等模型。然后,我们将通过交叉验证、网格搜索等技术,对模型的参数进行优化,以获得最佳的模型性能。
4. 模型训练与评估指标
在模型训练过程中,我们将使用训练数据集来训练模型,并使用验证数据集进行模型选择和参数优化。一旦模型确定后,我们将使用测试数据集来评估模型的性能。评估指标将根据问题的类型而定,可能包括准确率、精确率、召回率、F1得分、AUC-ROC等。
5. 模型性能提升策略
为了进一步提高模型的性能,我们将尝试不同的模型融合策略,如sackig、baggig等。我们还将尝试使用深度学习技术,如卷积神经网络、循环神经网络等,以捕捉更复杂的模式。我们还将考虑使用集成学习方法,如baggig和boosig,将多个模型的预测结果结合起来,以获得更好的性能。
6. 模型部署与实际应用
一旦模型的性能达到满意水平,我们将考虑将其部署到实际环境中。这可能涉及将模型集成到现有的系统中,或者开发一个新的系统来使用模型进行预测。在部署过程中,我们还需要考虑模型的实时性、可扩展性和健壮性等问题。
7. 经验总结与未来展望
通过本次实践案例,我们获得了许多宝贵的经验教训。例如,我们发现数据质量和特征工程对模型的性能有很大的影响;我们还发现某些模型在处理某些类型的数据时表现更好。这些经验将有助于我们在未来的项目中做出更明智的决策。随着技术的不断发展,我们期待看到更多的先进算法和更复杂的数据集出现。
 头条
头条 头条
头条 头条
头条 头条
头条 头条
头条 头条
头条 头条
头条 头条
头条
头条
头条 头条
头条