图数据库是专门用于存储巨大图网络并从中检索信息的数据库。它可以高效地将图中的数据存储为顶点(Vertex)和边(Edge),还可以为顶点和边附加属性(Property)。本文以样本数据集basketballplayer为例,通过nGQL操作和Python脚本构建图。数据[10]和代码[9]在参考文献中有详细介绍。
1。样本数据集简介
1.数据集架构
积分包括球员(球员)和球队(球队),边包括发球(球员->球队)和跟随(球员->球员):

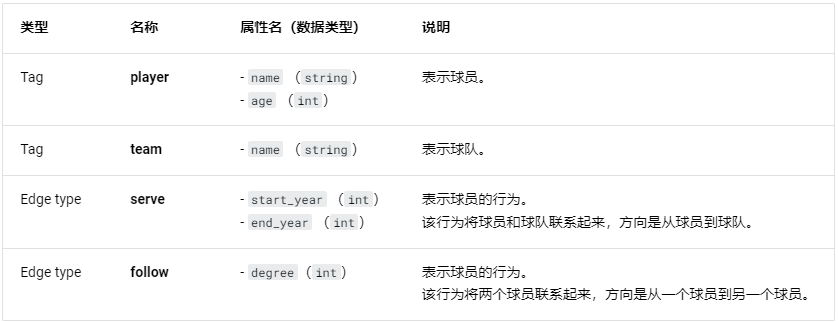
Player玩家积分数据包括player_id(玩家id)、age(年龄)和name(姓名):
player105 31 丹尼·格林
player109 34 蒂亚戈·斯普利特
player111 38 大卫·韦斯特
player118 30 拉塞尔·威斯布鲁克
player143 23 克里斯塔普斯·波尔津吉斯 player104 32 马可·贝里内利
player107 32 阿隆·贝恩斯
player116 34 勒布朗·詹姆斯
player120 29 詹姆斯·哈登
player125 41 马努·吉诺比利
3.vertex_team.csv
Team队积分数据包括team_id(球对id)和name(名字):
team204 马刺队
team218 猛龙队
team229 热火队
team202 火箭队
team208 国王队
team216 骑士队
team217 凯尔特人队
team223 尼克斯队
team224 活塞队
team205 雷霆队
4.edge_serve.csv
发球方数据包括player_id(球员ID)、team_id(球对ID)、start_year(开始年份)和end_year(结束年份):
player100 team204 1997 2016
player101 team204 1999 2018
player101 team215 2018 2019
player102 team203 20 06 2015
player102 team204 2015 2019
player103 team204 2017 2019
player103 team208 2013 2017
player103 team212 2006 2013
player103 team218 2013 2013
player104 team200 2007 2009
5.edge_follow.csv
player100player101 95
player100player125 95
player101player100 95
player101player102 90
player101player125 95 玩家102 玩家100 75
玩家102 玩家101 75
玩家103 玩家102 70
玩家104 玩家100 55
玩家104 玩家101 50
2.nGQL操作构建图
创建一个图形空间,包括名称和Vid Type,如下图:


//创建2个属性的Tag玩家
CREATE TAG玩家(name string,age int);
//创建1个属性的Tag团队
CREATE TAG团队(name string);
// 创建边 type follow,具有 1 个属性
CREATE EDGE follow( Degree int);
// 创建边 type serve ,具有 2 个属性属性
创建EDGE 服务(start_year int, end_year int);
创建完成后,在控制台通过NGQL查看点和边信息,如下图:
显示标签; // 列出当前图像空间中的所有标签
SHOW EDGES; // 列出当前图像空间中的所有Edges type
//查看每个Tag和Edge type的结构是否正确?
描述标签球员;
描述标签团队;
描述边缘跟随;
描述边缘发球;




通过任务列表查看导入信息,如下图:


通过NebulaGraph控制台,执行命令可以看到如下内容:

3。用于构建图表的 Python 脚本
上述操作都是通过nGQL命令来执行的。当数据量较大时,最好通过脚本来处理,如下图:
from m.gsm-guard.net import ConnectionPool
from nebula3.Config import Config
import numpy as np
import pandas as pd
config = Config() # 定义一个配置
config.max_connection_pool_size = 10 # 设置最大连接数
connection_pool = ConnectionPool() # 初始化连接池
# 如果给定的服务器没问题,则返回true,否则返回false
ok = connection_pool.init([('172.27.211.84', 9669)], config)
vertex_player_df = m.gsm-guard.net_csv( “C:/用户/管理员/下载/数据集/数据集/vertex_player.csv",标题=无,名称=['player_id','年龄', '名字'])
vertex_team_df = m.gsm-guard.net_csv(“C:/用户/管理员/下载/数据集/数据集/vertex_team.csv”,标题=无,名称= ['team_id ' , '名称'])
edge_follow_df = m.gsm-guard.net_csv("C:/用户/管理员/下载/数据集/数据集/edge_f ollow.csv",标题=无,名称=['player_id1','player_id2','学位'])
edge_serve_df= m.gsm-guard.net_csv("C:/Users/Administrator/Downloads/dataset/dataset/edge_serve.csv", header=无, names=['player_id', 'team_id', 'start_year', 'end_year'])
# 会话池,会话将自动释放
与connection_pool.session_context( 'root', 'nebula') 作为会话:
# basketballplayer_python space
会话.execute('如果不存在则创建空间`basketballplayer_python_test`( vid_type = FIXED_STRING(32))')
#结果= session.execute('显示空间')
# print(结果)
# 使用basketballplayer_python空间
session.execute('使用basketballplayer_python')
session.execute('如果不创建标签存在玩家(姓名字符串,年龄整数)' ) # 创建玩家标签
session.execute('CREATE TAG IF NOT EXISTS team(name string)') # 创建团队标签
session.execute('如果不存在则创建边缘遵循(度int)') # 创建跟随边
session.execute('CREATE EDGE IF NOT EXISTSserve(start_year int, end_year int)' ) #创建发球优势
# 从 CSV 文件中读取数据并将其插入到播放器标签中
for 索引,行in vertex_player_df.iterrows():
会议。执行('如果不存在则插入顶点玩家(姓名,年龄)值“{}”:(“{}”,{})'.format(行['player_id' ], row['name'], m.gsm-guard.net64(row['age'])))
# 从 C 从 SV 读取数据文件并插入到团队标签
for 索引,行 in vertex_team_df.iterrows():
session.execute() 'INSERT VERTEX IF NOT EXISTS 团队(名称)值 "{}":("{}")'.format(行['team_id'],行['名称']))
# 从CSV文件中读取数据,插入到followedge中
for索引,第inedge_follow_df.iter rows() :
会话.执行( '如果不存在则插入边缘遵循(度)VALUES "{}"->"{}":({})'.format(row['player_id1'], row['player_id2'], m.gsm-guard.net64(row[' Degree'])))
#从CSV文件中读取数据,插入服务边
for索引,第inedge_serve_df.iterrows():
session.execute() '如果不存在则插入边缘服务(start_year,end_year)值 "{}"->"{}":({}, {})'.format(row['player_id'], row['team_id' ], m.gsm-guard.net64(row['start_year']), m.gsm-guard.net64(row['end_year'])))
#关闭连接池 connection_pool.close()
通过NebulaGraph控制台,执行命令match (v:player) return v;。结果以表格形式呈现如下:


参考:
[1]规划架构:https://m.gsm-guard.net/3.3.0/nebula-studio/quick-start/st-ug-plan-schema/
[2] 导入数据:https://m.gsm-guard.net/3.6.0/nebula-studio/quick-start/st-ug-import-data/
[3]控制台界面:https://m.gsm-guard.net/3.6.0/nebula-studio/quick-start/st-ug-console/
[4] 操作图空间:https://m.gsm-guard.net/3.6.0/nebula-studio/manage-schema/st-ug-crud-space/
[5]操作标签(点型):https://m.gsm-guard.net/3.6.0/nebula-studio/manage-schema/st-ug-crud-tag/
[6] 操作边类型:https://m.gsm-guard.net/3.6.0/nebula-studio/manage-schema/st-ug-crud-edge-type/
[7] 操作索引:https://m.gsm-guard.net/3.6.0/nebula-studio/manage-schema/st-ug-crud-index/
[8] 查看Schema:https://m.gsm-guard.net/3.6.0/nebula-studio/manage-schema/st-ug-view-schema/
[9]本文源码:https://m.gsm-guard.net/ai408/nlp-engineering/blob/main/20230917_NLP工程公众号Article/NebulaGraph Tutorial/m.gsm-guard.net
[10]本文数据:m.gsm-guard.net:https://m.gsm-guard.net/f/2501739-944592417-0f75d0?p=2096(访问密码:2096)










 头条
头条 头条
头条 头条
头条 头条
头条 头条
头条 头条
头条 头条
头条 头条
头条 头条
头条 头条
头条


















